 |
Welcome to A!Die Software Studio |
IEEE 754 浮点数的表示精度探讨
2011-06-24 12:36:11
前言
从网上看到不少程序员对浮点数精度问题有很多疑问,在论坛上发贴询问,很多热心人给予了解答,但我发现一些解答中有些许小的错误和认识不当之处。我曾经做过数值算法程序,虽然基本可用,但是被浮点数精度问题所困扰;事情过后,我花了一点时间搜集资料,并仔细研究,有些心得体会,愿意与大家分享,希望对IEEE 754标准中的二进制浮点数精度及其相关问题给予较为详尽的解释。当然,文中任何错误由本人造成,由我承担,特此声明。
1、 什么是IEEE 754标准?
目前支持二进制浮点数的硬件和软件文档中,几乎都声称其浮点数实现符合IEEE 754标准。那么,什么是IEEE 754标准?
最权威的解释是IEEE754标准本身ANSI/IEEE Std 754-1985《IEEE Standard for Binary Floating-Point Arithmetic》,网上有PDF格式的文件,Google一下,下载即可。标准文本是英文的,总共才23页,有耐心的话可以仔细阅读。这里摘录前言中的一句:
This standard defines a family of commercially feasible ways for new systems to perform binary floating-point arithmetic。
其实是句废话,什么也没说。
IEEE 754标准的主要起草者是加州大学伯克利分校数学系教授William Kahan,他帮助Intel公司设计了8087浮点处理器(FPU),并以此为基础形成了IEEE 754标准,Kahan教授也因此获得了1987年的图灵奖。赞一句:IEEE 754浮点格式确实是天才的设计。Kahan教授的主页:http://www.cs.berkeley.edu/~wkahan/。
看看其它文献怎么说。
2、 IEEE 754标准规定了什么?
以下内容来自Sun公司的《Numerical Computation Guide-Sun Studio 11》的中文版《数值计算指南》,并加上本人的一点说明。说实话,该中文指南翻译得不太好,例如,round译成“四舍五入”。
IEEE 754 规定:
a) 两种基本浮点格式:单精度和双精度。
IEEE单精度格式具有24位有效数字,并总共占用32 位。IEEE双精度格式具有53位有效数字精度,并总共占用64位。
说明:基本浮点格式是固定格式,相对应的十进制有效数字分别为7位和17位。基本浮点格式对应的C/C++类型为float和double。
b) 两种扩展浮点格式:单精度扩展和双精度扩展。
此标准并未规定扩展格式的精度和大小,但它指定了最小精度和大小。例如,IEEE 双精度扩展格式必须至少具有64位有效数字,并总共占用至少79 位。
说明:虽然IEEE 754标准没有规定具体格式,但是实现者可以选择符合该规定的格式,一旦实现,则为固定格式。例如:x86 FPU是80位扩展精度,而Intel安腾FPU是82位扩展精度,都符合IEEE 754标准的规定。C/C++对于扩展双精度的相应类型是long double,但是,Microsoft Visual C++ 6.0版本以上的编译器都不支持该类型,long double和double一样,都是64位基本双精度,只能用其它C/C++编译器或汇编语言。
c) 浮点运算的准确度要求:加、减、乘、除、平方根、余数、将浮点格式的数舍入为整数值、在不同浮点格式之间转换、在浮点和整数格式之间转换以及比较。
求余和比较运算必须精确无误。其他的每种运算必须向其目标提供精确的结果,除非没有此类结果,或者该结果不满足目标格式。对于后一种情况,运算必须按照下面介绍的规定舍入模式的规则对精确结果进行最低限度的修改,并将经过此类修改的结果提供给运算的目标。
说明:IEEE 754没有规定基本算术运算(+、-、×、/ 等)的结果必须精确无误,因为对于IEEE 754的二进制浮点数格式,由于浮点格式长度固定,基本运算的结果几乎不可能精确无误。这里用三位精度的十进制加法来说明:
例1:a = 3.51,b = 0.234,求a+b = ?
a与b都是三位有效数字,但是,a+b的精确结果为3.744,是四位有效数字,对于该浮点格式只有三位精度,a+b的结果无法精确表示,只能近似表示,具体运算结果取决于舍入模式(见舍入模式的说明)。同理,由于浮点格式固定,对于其他基本运算,结果也几乎无法精确表示。
d) 在十进制字符串和两种基本浮点格式之一的二进制浮点数之间进行转换的准确度、单一性和一致性要求。
对于在指定范围内的操作数,这些转换必须生成精确的结果(如果可能的话),或者按照规定舍入模式的规则,对此类精确结果进行最低限度的修改。对于不在指定范围内的操作数,这些转换生成的结果与精确结果之间的差值不得超过取决于舍入模式的指定误差。
说明:这一条规定是针对十进制字符串表示的数据与二进制浮点数之间相互转换的规定,也是一般编程者最容易产生错觉的事情。因为人最熟悉的是十进制,以为对于任意十进制数,二进制都应该能精确表示,其实不然。本文主要目的就是揭密二进制浮点数所能够精确表示的十进制数,如果你以前没有想过这个问题,绝对让你吃惊。卖个关子先!
e) 五种类型的IEEE 浮点异常,以及用于向用户指示发生这些类型异常的条件。
五种类型的浮点异常是:无效运算、被零除、上溢、下溢和不精确。
说明:关于浮点异常,见Kahan教授的《Lecture Notes on IEEE 754》,这里我就不浪费口水了。
f) 四种舍入方向:
向最接近的可表示的值;当有两个最接近的可表示的值时首选“偶数”值;向负无穷大(向下);向正无穷大(向上)以及向0(截断)。
说明:舍入模式也是比较容易引起误解的地方之一。我们最熟悉的是四舍五入模式,但是,IEEE 754标准根本不支持,它的默认模式是最近舍入(Round to Nearest),它与四舍五入只有一点不同,对.5的舍入上,采用取偶数的方式。举例比较如下:
例2:
最近舍入模式:Round(0.5) = 0; Round(1.5) = 2; Round(2.5) = 2;
四舍五入模式:Round(0.5) = 1; Round(1.5) = 2; Round(2.5) = 3;
主要理由:由于字长有限,浮点数能够精确表示的数是有限的,因而也是离散的。在两个可以精确表示的相邻浮点数之间,必定存在无穷多实数是IEEE浮点数所无法精确表示的。如何用浮点数表示这些数,IEEE 754的方法是用距离该实数最近的浮点数来近似表示。但是,对于.5,它到0和1的距离是一样近,偏向谁都不合适,四舍五入模式取1,虽然银行在计算利息时,愿意多给0.5分钱,但是,它并不合理。例如:如果在求和计算中使用四舍五入,一直算下去,误差有可能越来越大。机会均等才公平,也就是向上和向下各占一半才合理,在大量计算中,从统计角度来看,高一位分别是偶数和奇数的概率正好是50% : 50%。至于为什么取偶数而不是奇数,大师Knuth有一个例子说明偶数更好,于是一锤定音。最近舍入模式在C/C++中没有相应的函数,当然,IEEE754以及x86 FPU的默认舍入模式是最近舍入,也就是每次浮点计算结果都采用最近舍入模式,除非用程序显式设置为其它三种舍入模式。
另外三种舍入模式,简要说明。
向0(截断)舍入:C/C++的类型转换。(int) 1.324 = 1,(int) -1.324 = -1;
向负无穷大(向下)舍入:C/C++函数floor()。例如:floor(1.324) = 1,floor(-1.324) = -2。
向正无穷大(向上)舍入:C/C++函数ceil()。ceil(1.324) = 2。Ceil(-1.324) = -1;
后两种舍入方法据说是为了数值计算中的区间算法,但很少听说哪个商业软件使用区间算法。
3、 十进制小数与二进制小数的相互转换
先看看十进制数与二进制数如何互相转换。用下标表示数的基(base),即d10表示十进制数,b2二进制数。则一个具有n+1位整数m位小数的十进制数d10表示为:
![]()
例3:
![]()
同理,一个具有n+ 1位整数m位小数的二进制数b2表示为:
例4:
二进制数转换成十进制数,比较容易,如例4。
十进制数转换成二进制数,是把整数部分和小数部分分别转换,整数部分用2除,取余数,小数部分用2乘,取整数位。
例5:把(13.125)10转换成二进制数
整数部分:![]() ,小数部分:
,小数部分:
因此,![]()
说明:C/C++语言的scanf()函数一般不采用这种方法。
一个十进制数能否用二进制浮点数精确表示,关键在于小数部分。我们来看一个最简单的小数![]() 能否精确表示。按照乘以2取整数位的方法,有:
能否精确表示。按照乘以2取整数位的方法,有:

得到一个无限循环的二进制小数![]() ,用有限位无法表示无限循环小数,因此,
,用有限位无法表示无限循环小数,因此,![]() 无法用IEEE 754浮点数精确表示。从中也可以看到:由于
无法用IEEE 754浮点数精确表示。从中也可以看到:由于
![]() ,
,
这四个数也无法精确表示。同理:
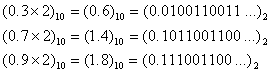
也无法用IEEE 754浮点数精确表示。
结论1:![]() 的9个小数中,只有0.5可以精确表示:
的9个小数中,只有0.5可以精确表示:![]() 。
。
可以把这个结论推广到一般情况:
结论2:任何下面的十进制数都无法用IEEE 754浮点数精确表示,必定存在误差。
![]()
如果![]() 的整数部分能精确表示且该数在浮点数的精度范围之内,则该数可以精确表示。
的整数部分能精确表示且该数在浮点数的精度范围之内,则该数可以精确表示。
4、 二进制小数能精确表示的十进制小数的基本规律
上述结论是由十进制数向二进制数转换而得到的,下面从二进制数向十进制数转换的角度来推演:

可以一直算下去,得到一个基本规律
结论3:一个十进制小数要能用浮点数精确表示,最后一位必须是5,因为1 除以2永远是0.5,当然这是必要条件,并非充分条件。
一个m位二进制小数能够精确表示的十进制小数有多少个呢?当然是![]() 个。推演如下:
个。推演如下:
![]()
一位二进制小数能够精确表示的小数只有![]() 个:
个:![]() 。
。
两位二进制小数能够精确表示的小数有![]() 个:
个:![]() 。
。
三位二进制小数能够精确表示的小数有![]() 个:
个:![]()
…
m位二进制小数能够精确表示的十进制小数就是![]() 个。而m位十进制小数有
个。而m位十进制小数有![]() 个,因此,能精确表示的十进制小数的比例是
个,因此,能精确表示的十进制小数的比例是![]() ,m越大,比例越小。以常用的单精度和双精度浮点数为例,m分别是24和53,则比例为:
,m越大,比例越小。以常用的单精度和双精度浮点数为例,m分别是24和53,则比例为:![]() 和
和![]() ,小到可以忽略不计。
,小到可以忽略不计。
5、 FAQ:C/C++库函数函数printf() 是如何忽悠我们的?
Q:既然绝大部分浮点小数都不能精确表示十进制小数,为什么printf()经常能打印出准确的值?
A:因为IEEE 754对二进制到十进制的转换有明确规定,见前面2.d)。而且函数printf()默认情况下只打印7位有效数字,在误差不大的情况下是没有问题的,但是,我们经常见到这样的结果“.xxxx999999”。用printf(“%.17lf”, …);可以让浮点数显出原形。
6、 与IEEE 754相关的标准
本文的结论基于IEEE 754标准,另外一个标准是IEEE 854,这个标准是关于十进制浮点数的,但没有规定具体格式,所以很少被采用。另外,从2000年开始,IEEE 754开始修订,被称为IEEE 754R(http://754r.ucbtest.org/),目的是融合IEEE 754和IEEE 854标准,已经在工作组内进行表决,还没有被IEEE表决通过,估计也快了。该标准在浮点格式方面的修订如下:
a) 加入了16位和128位的二进制浮点数格式。
b) 加入了十进制浮点数格式,采用了IBM公司(http://www2.hursley.ibm.com/decimal/)提出的格式,Intel公司也提出了自己的格式,但未被采纳,只留了口子。(标准从来都是企业利益博弈的产物)。
7、 是否该使用十进制浮点数?
Kahan教授的看法:一定要使用十进制浮点数,以避免人为错误。也就是这种错误:double d = 0.1;实际上,d≠0.1。
IBM公司的看法:在经济、金融和与人相关的程序中,使用十进制浮点数。但是,由于没有硬件支持,用软件实现的十进制浮点计算比硬件实现的二进制浮点计算要慢100-1000倍。由于被IEEE 754R所采纳,IBM公司将在下一代Power芯片中实现十进制FPU。(http://www2.hursley.ibm.com/decimal/)
8、 进一步阅读建议
本文讨论的是二进制浮点数的表示精度问题,对于计算精度,可以阅读David Goldberg的经典文章《What Every Computer Scientist Should Know About Floating-Point Arithmetic》,别以为“Scientist”是什么高级玩意儿,在这里是“初学者”,《数值计算指南》把该文作为附录。
总结
精确是偶然的,误差是必然的。如果做数值算法,惟一能做的就是误差不积累,其它的就不要奢望了。
▲评论
学习了

